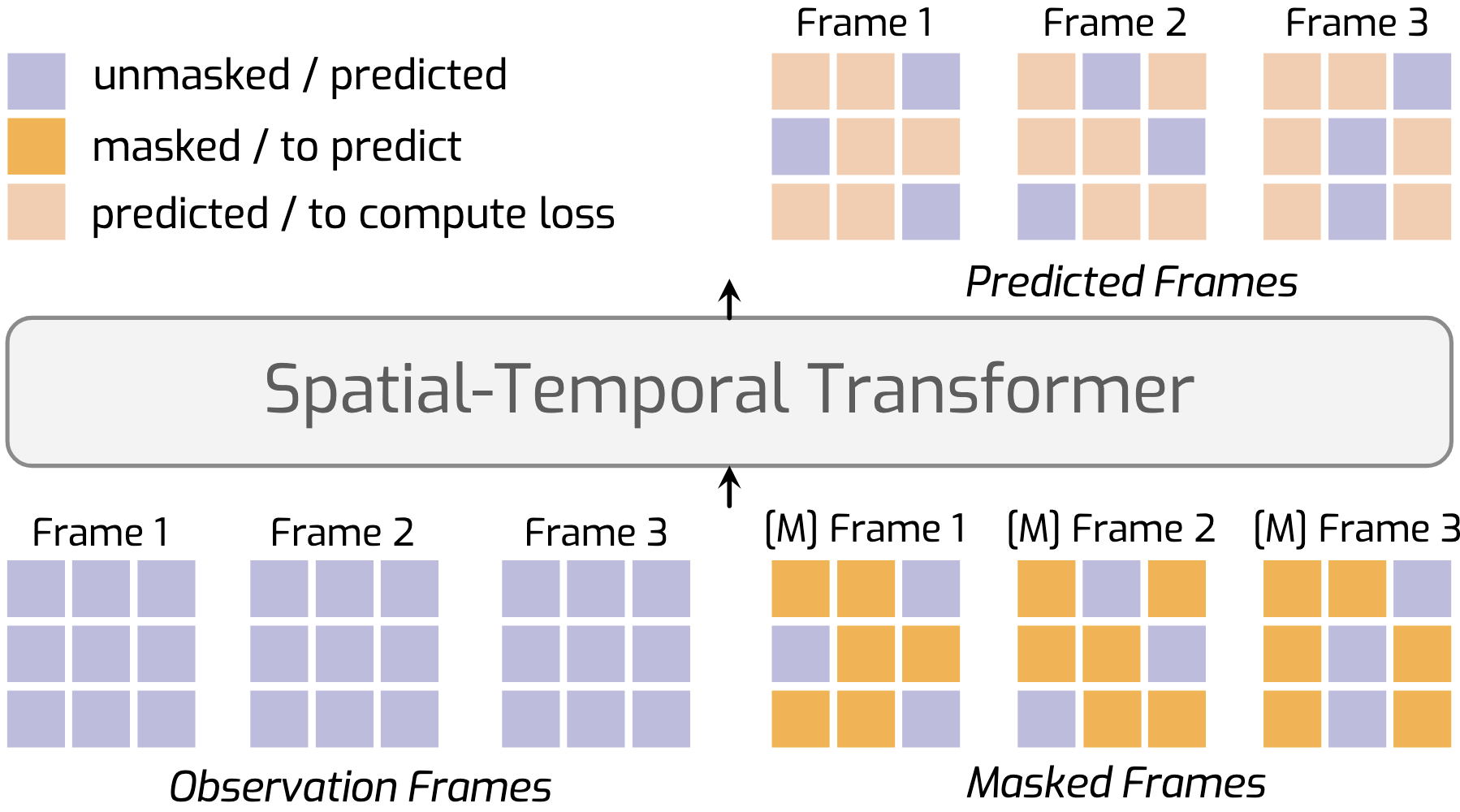
We introduce MAGI, a hybrid video generation framework that combines masked modeling for intra-frame generation with causal modeling for next-frame generation.
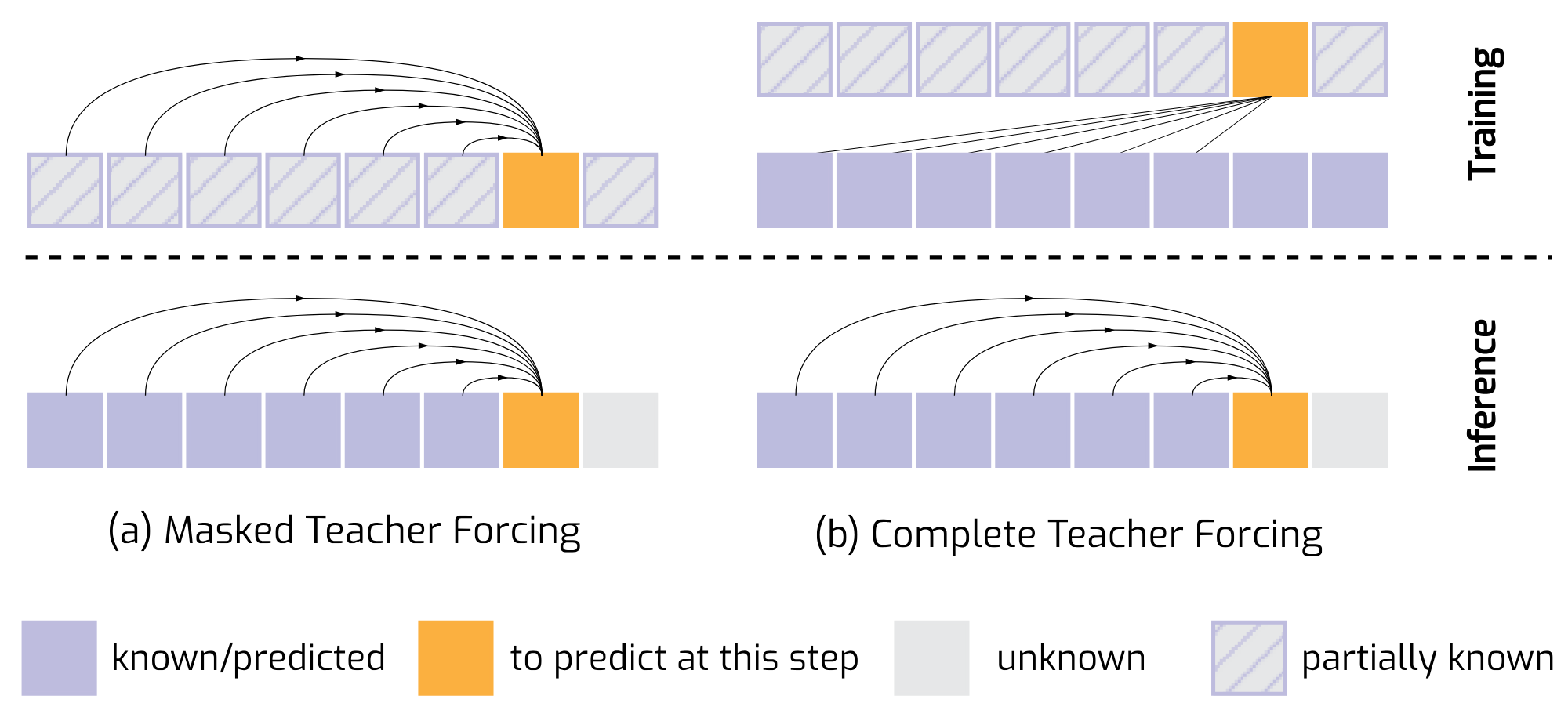
Our key innovation, Complete Teacher Forcing (CTF), conditions masked frames on complete observation frames rather than masked ones (namely Masked Teacher Forcing, MTF), enabling a smooth transition from token-level (patch-level) to frame-level autoregressive generation.
CTF significantly outperforms MTF, achieving a +23% improvement in FVD scores on first-frame conditioned video prediction. To address issues like exposure bias, we employ targeted training strategies, setting a new benchmark in autoregressive video generation. Experiments show that MAGI can generate long, coherent video sequences exceeding 100 frames, even when trained on as few as 16 frames, highlighting its potential for scalable, high-quality video generation.